 Главная
Главная
Как CYFER помог навести порядок в базе данных сельхозпроизводителя, повысив производительность на 50%
Проект создания AI-ассистента (AI-навигатора) поддержки клиентов первой линии для производителя сложного сельскохозяйственного оборудования стал результатом нового делового знакомства. Решение пришло вместе с осознанием проблемы: сотрудникам предприятия приходилось уделять слишком много времени на поиск информации и написание типовых ответов. Наш клиент понимал масштаб поставленной задачи с учетом специфики своих исходных данных и был готов ждать больше года. Нам же удалось выполнить основной объем работ за 2 месяца.
Как CYFER помог навести порядок в базе данных сельхозпроизводителя, повысив производительность на 50%
Проект создания AI-ассистента (AI-навигатора) поддержки клиентов первой линии для производителя сложного сельскохозяйственного оборудования стал результатом нового делового знакомства. Решение пришло вместе с осознанием проблемы: сотрудникам предприятия приходилось уделять слишком много времени на поиск информации и написание типовых ответов. Наш клиент понимал масштаб поставленной задачи с учетом специфики своих исходных данных и был готов ждать больше года. Нам же удалось выполнить основной объем работ за 2 месяца.
Сотрудники Заказчика тратили много времени на поиск информации в разрозненных и избыточных базах: 300 000+ документов, дублирование и разные форматы данных. Решением стала разработка AI-ассистента для бизнеса, который повысит скорость доступа к базе знаний и автоматизации рутинных процессов в компании.
Сотрудники Заказчика тратили много времени на поиск информации в разрозненных и избыточных базах: 300 000+ документов, дублирование и разные форматы данных. Решением стала разработка AI-ассистента для бизнеса, который повысит скорость доступа к базе знаний и автоматизации рутинных процессов в компании.
Предлагаемое решение представляло собой систему технологий искусственного интеллекта на базе Retrieval-Augmented Generation (RAG), которая позволяет эффективно искать и давать ответы на вопросы пользователям, используя базу данных документов.
Эта система включала в себя LLM (модель большого языка), которая генерирует ответы. Только вместо того, чтобы полагаться исключительно на обученные данные модели, она дополнительно подтягивает актуальную информацию из базы данных документов. Здесь можно выделить два ключевых этапа:
RAG обеспечивает актуальность ответа, так как система работает не только с заранее обученной моделью, но и с конкретной базой данных (документами, справочниками, инструкциями и т.д.). И даже если в LLM нет информации о запрашиваемом предмете, она подтянет ее из той самой базы.
Эта система включала в себя LLM (модель большого языка), которая генерирует ответы. Только вместо того, чтобы полагаться исключительно на обученные данные модели, она дополнительно подтягивает актуальную информацию из базы данных документов. Здесь можно выделить два ключевых этапа:
- Поиск релевантной информации. Пользователь делает запрос (например, через интерфейс). Алгоритмы RAG ищут ответы по базе данных документов, выбирая наиболее подходящие фрагменты.
- Создание ответа. Используя найденную информацию, LLM формирует текстовый ответ, который будет точным, понятным и содержательным.
RAG обеспечивает актуальность ответа, так как система работает не только с заранее обученной моделью, но и с конкретной базой данных (документами, справочниками, инструкциями и т.д.). И даже если в LLM нет информации о запрашиваемом предмете, она подтянет ее из той самой базы.
Чтобы реализовать это, мы создаем универсальную API-интеграцию с искусственным интеллектом, которая позволяет подключить AI-навигатор к любым приложениям: корпоративный чат, мобильное приложение, внутренняя система компании или веб-сайт. Система легко интегрируется благодаря API.
На начальном этапе клиент - компания, которая работает с большими объемами данных - получает ее с простым и удобным интерфейсом на базе Gradio (это инструмент для быстрой визуализации и тестирования решений AI) — там он может изучать и отлаживать функционал сервиса.
Стек используемых технологий:
На начальном этапе клиент - компания, которая работает с большими объемами данных - получает ее с простым и удобным интерфейсом на базе Gradio (это инструмент для быстрой визуализации и тестирования решений AI) — там он может изучать и отлаживать функционал сервиса.
Стек используемых технологий:
- Эмбединги BAAI/bge-m3, LLM Mistral Nemo
- БД Postgres
- API Python/FastAPI
Как работает AI-навигатор
Предлагаемое решение представляло собой систему технологий искусственного интеллекта на базе Retrieval-Augmented Generation (RAG), которая позволяет эффективно искать и давать ответы на вопросы пользователям, используя базу данных документов.
Эта система включала в себя LLM (модель большого языка), которая генерирует ответы. Только вместо того, чтобы полагаться исключительно на обученные данные модели, она дополнительно подтягивает актуальную информацию из базы данных документов. Здесь можно выделить два ключевых этапа:
RAG обеспечивает актуальность ответа, так как система работает не только с заранее обученной моделью, но и с конкретной базой данных (документами, справочниками, инструкциями и т.д.). И даже если в LLM нет информации о запрашиваемом предмете, она подтянет ее из той самой базы.
Эта система включала в себя LLM (модель большого языка), которая генерирует ответы. Только вместо того, чтобы полагаться исключительно на обученные данные модели, она дополнительно подтягивает актуальную информацию из базы данных документов. Здесь можно выделить два ключевых этапа:
- Поиск релевантной информации. Пользователь делает запрос (например, через интерфейс). Алгоритмы RAG ищут ответы по базе данных документов, выбирая наиболее подходящие фрагменты.
- Создание ответа. Используя найденную информацию, LLM формирует текстовый ответ, который будет точным, понятным и содержательным.
RAG обеспечивает актуальность ответа, так как система работает не только с заранее обученной моделью, но и с конкретной базой данных (документами, справочниками, инструкциями и т.д.). И даже если в LLM нет информации о запрашиваемом предмете, она подтянет ее из той самой базы.
Чтобы реализовать это, мы создаем универсальную API-интеграцию с искусственным интеллектом, которая позволяет подключить AI-навигатор к любым приложениям: корпоративный чат, мобильное приложение, внутренняя система компании или веб-сайт. Система легко интегрируется благодаря API.
На начальном этапе клиент - компания, которая работает с большими объемами данных - получает ее с простым и удобным интерфейсом на базе Gradio (это инструмент для быстрой визуализации и тестирования решений AI) — там он может изучать и отлаживать функционал сервиса.
Стек используемых технологий:
На начальном этапе клиент - компания, которая работает с большими объемами данных - получает ее с простым и удобным интерфейсом на базе Gradio (это инструмент для быстрой визуализации и тестирования решений AI) — там он может изучать и отлаживать функционал сервиса.
Стек используемых технологий:
- Эмбединги BAAI/bge-m3, LLM Mistral Nemo
- БД Postgres
- API Python/FastAPI
Как работает AI-навигатор
Примеры использования нашего решения:
- Корпоративные чаты. Сотрудники могут задавать вопросы о внутренних процессах (пример: «Какие текущие инструкции по командировкам?») — система выдаст точный и актуальный ответ.
- Обслуживание клиентов. Система работает как умный чат-бот, предоставляющий ответы на вопросы пользователей на основе документации компании.
- Юридические или технические консультации. AI-навигатор быстро находит необходимую информацию, ссылаясь на внутренние или публичные документы, чтобы предоставить точные и полные ответы.
Преимущества решения:
Это решение практически универсально, так как может адаптироваться под любые процессы, где требуется быстрый поиск и разъяснение информации. Для компаний, работающих с большими объемами данных, внедрение AI-ассистента на базе RAG оптимизирует бизнес-процессы и уменьшает затраты времени сотрудников до 60%.
- Интерактивность. Пользователь чувствует, будто взаимодействует с «умным помощником».
- Интеграция. API делает решение гибким: его легко встраивать в текущую экосистему компании.
- Экономия времени. Быстрый доступ к большим объёмам информации.
- Гибкость. Gradio на начальном этапе позволяет удобно использовать интерфейс, который позже можно заменить на кастомизированный, под нужды компании.
Это решение практически универсально, так как может адаптироваться под любые процессы, где требуется быстрый поиск и разъяснение информации. Для компаний, работающих с большими объемами данных, внедрение AI-ассистента на базе RAG оптимизирует бизнес-процессы и уменьшает затраты времени сотрудников до 60%.
Почему бизнесу нужен AI-ассистент: три ключевых преимущества
Почему бизнесу нужен
AI-ассистент: три ключевых преимущества
Примеры использования нашего решения:
- Корпоративные чаты. Сотрудники могут задавать вопросы о внутренних процессах (пример: «Какие текущие инструкции по командировкам?») — система выдаст точный и актуальный ответ.
- Обслуживание клиентов. Система работает как умный чат-бот, предоставляющий ответы на вопросы пользователей на основе документации компании.
- Юридические или технические консультации. AI-навигатор быстро находит необходимую информацию, ссылаясь на внутренние или публичные документы, чтобы предоставить точные и полные ответы.
Преимущества решения:
Это решение практически универсально, так как может адаптироваться под любые процессы, где требуется быстрый поиск и разъяснение информации. Для компаний, работающих с большими объемами данных, внедрение AI-ассистента на базе RAG оптимизирует бизнес-процессы и уменьшает затраты времени сотрудников до 60%.
- Интерактивность. Пользователь чувствует, будто взаимодействует с «умным помощником».
- Интеграция. API делает решение гибким: его легко встраивать в текущую экосистему компании.
- Экономия времени. Быстрый доступ к большим объёмам информации.
- Гибкость. Gradio на начальном этапе позволяет удобно использовать интерфейс, который позже можно заменить на кастомизированный, под нужды компании.
Это решение практически универсально, так как может адаптироваться под любые процессы, где требуется быстрый поиск и разъяснение информации. Для компаний, работающих с большими объемами данных, внедрение AI-ассистента на базе RAG оптимизирует бизнес-процессы и уменьшает затраты времени сотрудников до 60%.
Почему бизнесу нужен AI-ассистент: три ключевых преимущества
Почему бизнесу нужен
AI-ассистент: три ключевых преимущества
Извлечение информации
1
Извлечение информации
1
Вернемся к кейсу.
Собрать данные с более чем 300 000 файлов для их дальнейшей обработки оказалось не так просто. Порядка 70% из них были дубликатами, а также:
В документах оказалось много таблиц, которые плохо воспринимаются искусственным интеллектом. Мы составляли отдельные промты и скрипты, чтобы преобразовать их в удобный читаемый код для машины.
В рамках интеграции системы RAG с AI-навигатором, формирование базы промтов и скриптов позволяет адаптировать информацию из базы знаний в структурированный вид, который легко обработать машиной. Приведем парочку примеров таких промтов. и скриптов
Собрать данные с более чем 300 000 файлов для их дальнейшей обработки оказалось не так просто. Порядка 70% из них были дубликатами, а также:
- Файлы размещались на разных источниках и были представлены в нескольких форматах: pdf, doc, docx, txt, xlsx, pptx и др. В частности, предстояло извлечь информацию из роликов компании на YouTube, так как у клиента не сохранились их оригиналы на локальных носителях. Мы автоматизировали процесс скачивания и расшифровки аудио прямо с видеохостинга, после чего подали результаты в LLM для приведения текста в порядок и разбивки на логические блоки.
- Также требовалось считать информацию с технических документов (например, инструкций по эксплуатации), проанализировать порядка 25 000 диалогов сотрудников первой линии и надиктованные записи.
В документах оказалось много таблиц, которые плохо воспринимаются искусственным интеллектом. Мы составляли отдельные промты и скрипты, чтобы преобразовать их в удобный читаемый код для машины.
В рамках интеграции системы RAG с AI-навигатором, формирование базы промтов и скриптов позволяет адаптировать информацию из базы знаний в структурированный вид, который легко обработать машиной. Приведем парочку примеров таких промтов. и скриптов
Пример промта: "Вопросы по доступу в систему"
Скрипт для сотрудников первой линии
Приветствие и уточнение проблемы: «Добрый день! Я помогу вам разобраться с доступом. Вы не можете авторизоваться в системе, правильно? Расскажите, что вы видите на экране, когда пытаетесь войти.»
Выяснение контекста: «Пожалуйста, уточните: вы используете правильный логин? Сообщение об ошибке, если оно есть, содержит текст или код?»
Стандартные проверки: «Давайте попробуем следующие шаги:
Если проблема не решена: «Если ничего не помогает, я вышлю вам инструкции для сброса пароля. Если после этого проблема сохранится, я передам запрос в техническую поддержку.»
Приветствие и уточнение проблемы: «Добрый день! Я помогу вам разобраться с доступом. Вы не можете авторизоваться в системе, правильно? Расскажите, что вы видите на экране, когда пытаетесь войти.»
Выяснение контекста: «Пожалуйста, уточните: вы используете правильный логин? Сообщение об ошибке, если оно есть, содержит текст или код?»
Стандартные проверки: «Давайте попробуем следующие шаги:
- Убедитесь, что клавиатура переключена на правильный язык.
- Проверьте, включена ли клавиша Caps Lock.
- Смените устройство или браузер и попробуйте снова.»
Если проблема не решена: «Если ничего не помогает, я вышлю вам инструкции для сброса пароля. Если после этого проблема сохранится, я передам запрос в техническую поддержку.»

Вернемся к кейсу.
Собрать данные с более чем 300 000 файлов для их дальнейшей обработки оказалось не так просто. Порядка 70% из них были дубликатами, а также:
В документах оказалось много таблиц, которые плохо воспринимаются искусственным интеллектом. Мы составляли отдельные промты и скрипты, чтобы преобразовать их в удобный читаемый код для машины.
В рамках интеграции системы RAG с AI-навигатором, формирование базы промтов и скриптов позволяет адаптировать информацию из базы знаний в структурированный вид, который легко обработать машиной. Приведем парочку примеров таких промтов. и скриптов
Собрать данные с более чем 300 000 файлов для их дальнейшей обработки оказалось не так просто. Порядка 70% из них были дубликатами, а также:
- Файлы размещались на разных источниках и были представлены в нескольких форматах: pdf, doc, docx, txt, xlsx, pptx и др. В частности, предстояло извлечь информацию из роликов компании на YouTube, так как у клиента не сохранились их оригиналы на локальных носителях. Мы автоматизировали процесс скачивания и расшифровки аудио прямо с видеохостинга, после чего подали результаты в LLM для приведения текста в порядок и разбивки на логические блоки.
- Также требовалось считать информацию с технических документов (например, инструкций по эксплуатации), проанализировать порядка 25 000 диалогов сотрудников первой линии и надиктованные записи.
В документах оказалось много таблиц, которые плохо воспринимаются искусственным интеллектом. Мы составляли отдельные промты и скрипты, чтобы преобразовать их в удобный читаемый код для машины.
В рамках интеграции системы RAG с AI-навигатором, формирование базы промтов и скриптов позволяет адаптировать информацию из базы знаний в структурированный вид, который легко обработать машиной. Приведем парочку примеров таких промтов. и скриптов
Пример промта: "Вопросы по доступу в систему"
Скрипт для сотрудников первой линии
Приветствие и уточнение проблемы: «Добрый день! Я помогу вам разобраться с доступом. Вы не можете авторизоваться в системе, правильно? Расскажите, что вы видите на экране, когда пытаетесь войти.»
Выяснение контекста: «Пожалуйста, уточните: вы используете правильный логин? Сообщение об ошибке, если оно есть, содержит текст или код?»
Стандартные проверки: «Давайте попробуем следующие шаги:
Если проблема не решена: «Если ничего не помогает, я вышлю вам инструкции для сброса пароля. Если после этого проблема сохранится, я передам запрос в техническую поддержку.»
Приветствие и уточнение проблемы: «Добрый день! Я помогу вам разобраться с доступом. Вы не можете авторизоваться в системе, правильно? Расскажите, что вы видите на экране, когда пытаетесь войти.»
Выяснение контекста: «Пожалуйста, уточните: вы используете правильный логин? Сообщение об ошибке, если оно есть, содержит текст или код?»
Стандартные проверки: «Давайте попробуем следующие шаги:
- Убедитесь, что клавиатура переключена на правильный язык.
- Проверьте, включена ли клавиша Caps Lock.
- Смените устройство или браузер и попробуйте снова.»
Если проблема не решена: «Если ничего не помогает, я вышлю вам инструкции для сброса пароля. Если после этого проблема сохранится, я передам запрос в техническую поддержку.»
Пример промта: "Запрос информации из корпоративной базы знаний"
Скрипт для сотрудников первой линии
Инструкции для сотрудника: «Для получения ответа на ваш вопрос через базу знаний вы можете использовать голосовой запрос. Например, скажите: 'Где найти инструкцию для работы с CRM-системой?' или 'Покажи справку по теме начислений.'»
Формализация запроса: «Когда вы запрашиваете информацию, старайтесь быть максимально конкретным. Например, вместо 'Как работает система?' лучше уточнять: 'Как изменить данные клиента в CRM?'»
Ответ на запрос: «Система выдает пошаговую инструкцию. Если проблема сохраняется или информация не найдена, вам будет предложено связаться с технической поддержкой или перейти на вторую линию помощи.»
Инструкции для сотрудника: «Для получения ответа на ваш вопрос через базу знаний вы можете использовать голосовой запрос. Например, скажите: 'Где найти инструкцию для работы с CRM-системой?' или 'Покажи справку по теме начислений.'»
Формализация запроса: «Когда вы запрашиваете информацию, старайтесь быть максимально конкретным. Например, вместо 'Как работает система?' лучше уточнять: 'Как изменить данные клиента в CRM?'»
Ответ на запрос: «Система выдает пошаговую инструкцию. Если проблема сохраняется или информация не найдена, вам будет предложено связаться с технической поддержкой или перейти на вторую линию помощи.»
Пример промта: "Обработка надиктованной жалобы на техническую проблему"
Скрипт для сотрудников первой линии
Извлечение ключевой информации из запроса: AI-навигатор автоматически выделяет ключевые моменты:
Шаги по устранению проблемы: «Уточните у клиента:
Передача информации на следующую линию: «Если проблема не решается, передайте запрос в техническую поддержку со следующими данными:
Извлечение ключевой информации из запроса: AI-навигатор автоматически выделяет ключевые моменты:
- Дата и время сбоя: «Например, пользователь сообщил: 'Система перестала работать 15 мая в 14:30.'»
- Описание проблемы: «Например: 'При загрузке данных появляется ошибка с кодом 503.'»
Шаги по устранению проблемы: «Уточните у клиента:
- Вы пытались перезагрузить систему?
- Проблема проявляется только у вас или у других коллег?
- Можете ли вы попробовать другую сеть (например, мобильный интернет)?»
Передача информации на следующую линию: «Если проблема не решается, передайте запрос в техническую поддержку со следующими данными:
- Дата и время сбоя.
- Описание действия, которое вызвало сбой.

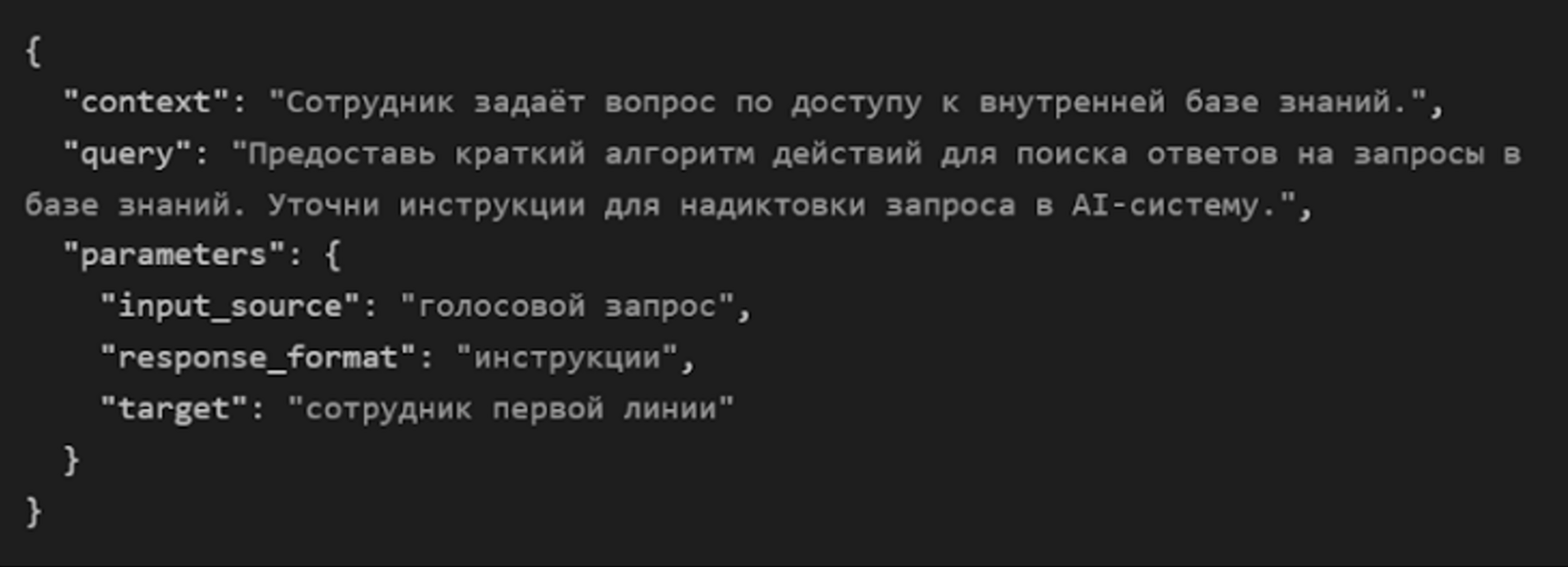
Эти примеры демонстрируют, как можно обрабатывать пользовательские запросы, оформлять их в формате, удобном для AI-системы, и предоставлять сотрудникам первой линии понятные скрипты для общения с клиентами и решения их проблем.
Возникла сложность с разбиением извлекаемой информации на семантические блоки, необходимые для подачи знаний в контекстное окно, — желательно было сделать их законченными для использования технологии RAG. Есть несколько подходов к разбиению (по количеству символов, по символу-разделителю, деление при помощи LLM, на основе семантического анализа/близости и т.д.), но не один из них не смог бы обеспечить необходимого качества.
Возникла сложность с разбиением извлекаемой информации на семантические блоки, необходимые для подачи знаний в контекстное окно, — желательно было сделать их законченными для использования технологии RAG. Есть несколько подходов к разбиению (по количеству символов, по символу-разделителю, деление при помощи LLM, на основе семантического анализа/близости и т.д.), но не один из них не смог бы обеспечить необходимого качества.
Поэтому нам пришлось сначала разбивать информацию на достаточно большие блоки (2-3 тысячи символов), согласно форматированию и с попыткой сохранить смысл, позже — на более мелкие блоки-чанки объемом 500-700 символов. Последние больше подходят для поиска, к тому же существуют ограничения некоторых эмбеддингов на длину текста для векторизации.
Так как ассистент должен был владеть актуальной информацией, параллельно мы автоматизировали работу контейнера для последующего автоматического обновления базы знаний.
Весь этап занял около недели и завершился успешно. Из серверных технологий для контейнеризации мы использовали программу Docker, для инференса LLM — vLLM.
Так как ассистент должен был владеть актуальной информацией, параллельно мы автоматизировали работу контейнера для последующего автоматического обновления базы знаний.
Весь этап занял около недели и завершился успешно. Из серверных технологий для контейнеризации мы использовали программу Docker, для инференса LLM — vLLM.
Эти примеры демонстрируют, как можно обрабатывать пользовательские запросы, оформлять их в формате, удобном для AI-системы, и предоставлять сотрудникам первой линии понятные скрипты для общения с клиентами и решения их проблем.
Возникла сложность с разбиением извлекаемой информации на семантические блоки, необходимые для подачи знаний в контекстное окно, — желательно было сделать их законченными для использования технологии RAG. Есть несколько подходов к разбиению (по количеству символов, по символу-разделителю, деление при помощи LLM, на основе семантического анализа/близости и т.д.), но не один из них не смог бы обеспечить необходимого качества.
Возникла сложность с разбиением извлекаемой информации на семантические блоки, необходимые для подачи знаний в контекстное окно, — желательно было сделать их законченными для использования технологии RAG. Есть несколько подходов к разбиению (по количеству символов, по символу-разделителю, деление при помощи LLM, на основе семантического анализа/близости и т.д.), но не один из них не смог бы обеспечить необходимого качества.
Поэтому нам пришлось сначала разбивать информацию на достаточно большие блоки (2-3 тысячи символов), согласно форматированию и с попыткой сохранить смысл, позже — на более мелкие блоки-чанки объемом 500-700 символов. Последние больше подходят для поиска, к тому же существуют ограничения некоторых эмбеддингов на длину текста для векторизации.
Так как ассистент должен был владеть актуальной информацией, параллельно мы автоматизировали работу контейнера для последующего автоматического обновления базы знаний.
Весь этап занял около недели и завершился успешно. Из серверных технологий для контейнеризации мы использовали программу Docker, для инференса LLM — vLLM.
Так как ассистент должен был владеть актуальной информацией, параллельно мы автоматизировали работу контейнера для последующего автоматического обновления базы знаний.
Весь этап занял около недели и завершился успешно. Из серверных технологий для контейнеризации мы использовали программу Docker, для инференса LLM — vLLM.
Работа над "проблемами"
2
Работа над "проблемами"
2
На следующем этапе нами были получены эталонные вопросы и ответы, которые внедрялись в базу AI-ассистента. С помощью большой языковой модели, LLM, мы провели оценку системы чат-бота с использованием ряда метрик:
Необходимая для нормальной работы ассистента точность ответов на тестовые вопросы — 90% и выше. Нам не удавалось ее добиться и понять, в чем дело, пока мы не начали просматривать данные вручную. Далее нами была произведена автоматизация процесса оценки обеспеченности контекстом эталонных вопросов на основе тех же эталонных ответов.
- язык;
- полнота ответов;
- их точность и т.д.
Необходимая для нормальной работы ассистента точность ответов на тестовые вопросы — 90% и выше. Нам не удавалось ее добиться и понять, в чем дело, пока мы не начали просматривать данные вручную. Далее нами была произведена автоматизация процесса оценки обеспеченности контекстом эталонных вопросов на основе тех же эталонных ответов.
Выяснилось, что эталонные ответы не содержатся или не полностью представлены в исходных файлах, которые предоставила компания. Для решения проблемы со стороны клиента была проделана большая работа по заполнению и актуализации регламентирующих документов. Приведение данных в порядок стало полезным не только для нашей дальнейшей работы над ассистентом, но и для самого заказчика.
Интенсивная работа по закрытию «пробелов» заняла около месяца. Итог — достижение показателя точности ответов в 92%.
Интенсивная работа по закрытию «пробелов» заняла около месяца. Итог — достижение показателя точности ответов в 92%.
На следующем этапе нами были получены эталонные вопросы и ответы, которые внедрялись в базу AI-ассистента. С помощью большой языковой модели, LLM, мы провели оценку системы чат-бота с использованием ряда метрик:
Необходимая для нормальной работы ассистента точность ответов на тестовые вопросы — 90% и выше. Нам не удавалось ее добиться и понять, в чем дело, пока мы не начали просматривать данные вручную. Далее нами была произведена автоматизация процесса оценки обеспеченности контекстом эталонных вопросов на основе тех же эталонных ответов.
- язык;
- полнота ответов;
- их точность и т.д.
Необходимая для нормальной работы ассистента точность ответов на тестовые вопросы — 90% и выше. Нам не удавалось ее добиться и понять, в чем дело, пока мы не начали просматривать данные вручную. Далее нами была произведена автоматизация процесса оценки обеспеченности контекстом эталонных вопросов на основе тех же эталонных ответов.
Выяснилось, что эталонные ответы не содержатся или не полностью представлены в исходных файлах, которые предоставила компания. Для решения проблемы со стороны клиента была проделана большая работа по заполнению и актуализации регламентирующих документов. Приведение данных в порядок стало полезным не только для нашей дальнейшей работы над ассистентом, но и для самого заказчика.
Интенсивная работа по закрытию «пробелов» заняла около месяца. Итог — достижение показателя точности ответов в 92%.
Интенсивная работа по закрытию «пробелов» заняла около месяца. Итог — достижение показателя точности ответов в 92%.
Расширение контекста
3
Расширение контекста
3
Существенной проблемой при тестировании эталонных вопросов стала нехватка вкладываемой в них информации. То, как человек их формулирует и понимает, может иметь огромную разницу. В результате возникают перекосы и несоответствие вопросов и ответов к ним. К тому же местами отсутствовала или оказывалась противоречивой информация в документах.
Чаще всего пользователь задает вопрос максимально кратко, на уровне ключевых слов, как если бы вводил его в поисковую строку браузера. При этом контекст может не считываться, хотя именно он представляет собой большую ценность.
Чаще всего пользователь задает вопрос максимально кратко, на уровне ключевых слов, как если бы вводил его в поисковую строку браузера. При этом контекст может не считываться, хотя именно он представляет собой большую ценность.
Чтобы чат-бот понимал вопросы «шире», мы научили его их расшифровке, раскрытию и дополнению. Составляли специальные примеры и образцы, обогащали данные контентом:
Прием носит название Few-Shot. Используя его, мы отбирали ранее расшифрованные «вопросы-ответы», подавали их в виде промптов LLM и просили построить по аналогии полные вопросы. Это позволило искусственному интеллекту лучше понимать контекст и давать более полные ответы.
- кто пользователь;
- какая у него история поиска;
- что ему может быть интересно и т.д.
Прием носит название Few-Shot. Используя его, мы отбирали ранее расшифрованные «вопросы-ответы», подавали их в виде промптов LLM и просили построить по аналогии полные вопросы. Это позволило искусственному интеллекту лучше понимать контекст и давать более полные ответы.
Существенной проблемой при тестировании эталонных вопросов стала нехватка вкладываемой в них информации. То, как человек их формулирует и понимает, может иметь огромную разницу. В результате возникают перекосы и несоответствие вопросов и ответов к ним. К тому же местами отсутствовала или оказывалась противоречивой информация в документах.
Чаще всего пользователь задает вопрос максимально кратко, на уровне ключевых слов, как если бы вводил его в поисковую строку браузера. При этом контекст может не считываться, хотя именно он представляет собой большую ценность.
Чаще всего пользователь задает вопрос максимально кратко, на уровне ключевых слов, как если бы вводил его в поисковую строку браузера. При этом контекст может не считываться, хотя именно он представляет собой большую ценность.
Чтобы чат-бот понимал вопросы «шире», мы научили его их расшифровке, раскрытию и дополнению. Составляли специальные примеры и образцы, обогащали данные контентом:
Прием носит название Few-Shot. Используя его, мы отбирали ранее расшифрованные «вопросы-ответы», подавали их в виде промптов LLM и просили построить по аналогии полные вопросы. Это позволило искусственному интеллекту лучше понимать контекст и давать более полные ответы.
- кто пользователь;
- какая у него история поиска;
- что ему может быть интересно и т.д.
Прием носит название Few-Shot. Используя его, мы отбирали ранее расшифрованные «вопросы-ответы», подавали их в виде промптов LLM и просили построить по аналогии полные вопросы. Это позволило искусственному интеллекту лучше понимать контекст и давать более полные ответы.
Результат
+
Результат
+
Несмотря на трудности, команда CYFER провела качественную подготовку данных и их внедрение в ассистент. Компания получила наш готовый продукт — AI-навигатор по Базе знаний, обработку и хранение данных которой мы также помогли систематизировать. Посещаемость корпоративного портала и «Википедии» в первые месяцы упала примерно вдвое — в них отпала необходимость, поскольку бот давал ответы быстрее и с приемлемой точностью.
Вместе со скоростью увеличились производительность и точность принимаемых решений. Благодаря сотрудничеству с нами в регламентирующих документах компании был наведен порядок, в том числе в их содержании. Клиент остался доволен. Вскоре после завершения проекта он обратился к нам за помощью в разработке других сервисов.
Несмотря на трудности, команда CYFER провела качественную подготовку данных и их внедрение в ассистент. Компания получила наш готовый продукт — AI-навигатор по Базе знаний, обработку и хранение данных которой мы также помогли систематизировать. Посещаемость корпоративного портала и «Википедии» в первые месяцы упала примерно вдвое — в них отпала необходимость, поскольку бот давал ответы быстрее и с приемлемой точностью.
Вместе со скоростью увеличились производительность и точность принимаемых решений. Благодаря сотрудничеству с нами в регламентирующих документах компании был наведен порядок, в том числе в их содержании. Клиент остался доволен. Вскоре после завершения проекта он обратился к нам за помощью в разработке других сервисов.
Вопросы по внедрению технологии RAG и LLM
?
Вопросы по внедрению технологии RAG и LLM
?
Сроки внедрения зависят от сложности инфраструктуры и объёма данных, с которыми предстоит работать. В среднем, процесс адаптации занимает от 4 до 12 недель. Мы выделяем этапы: аудит данных, настройка инфраструктуры, тестирование модели на выбранных данных и обучение сотрудников. Мы обеспечиваем минимизацию простоев в процессе работы.
RAG и LLM могут быть адаптированы под строгие требования безопасности, такие как локальная обработка данных (On-Premise), ограничение передачи данных в сеть и даже шифрование. Интеграция происходит с учётом всех стандартов безопасности, таких как GDPR или ISO 27001. Это позволяет выполнять обработку данных только внутри защищенной среды компании.
Уже в первый месяц вы увидите эффект:
- Оптимизация времени обработки информации, благодаря быстрому доступу к релевантным данным.
- Снижение нагрузки на сотрудников, так как модели справляются с рутинными задачами.
- Повышение точности аналитики и принятия решений.
- Для измерения эффективности мы внедряем ключевые показатели (KPI), такие как время на поиск информации, количество разрешённых запросов пользователей и увеличение производительности.
В отличие от стандартных LLM, которые генерируют ответы только на основе имеющихся знаний без проверки актуальности, RAG использует специализированные датасеты компании. Это позволяет:
- Получать точные и актуальные данные даже из нестандартной корпоративной базы.
- Уменьшить вероятность "галлюцинаций" модели (когда она генерирует ошибочные или фантазийные ответы).
Мы предоставляем полную поддержку, включающую обучение персонала и техническое сопровождение на всех этапах. Также возможно создание центра компетенции, который обеспечит адаптацию вашего внутреннего IT-отдела для работы с системой.
Модели RAG и LLM решают задачи именно там, где другие решения не справлялись: работа с массивами специализированных данных, высокая скорость обработки и контекстуальная генерация текстов. В отличие от универсальных решений, эта система адаптируется под конкретные бизнес-кейсы вашего предприятия, благодаря чему окупаемость обеспечивается в течение первых 6-12 месяцев.
Мы учитываем перспективы расширения и обновления в нашем решении. LLM-модели и RAG можно донастраивать по мере увеличения объёмов данных или изменения бизнес-процессов. Мы также консультируем вас по появлению новых трендов или подходов, чтобы ваша система всегда оставалась актуальной.
Стоимость интеграции варьируется от бюджета компании и уровня сложности задачи. Мы предлагаем модульный подход, начиная с малого функционала для тестирования и контроля эффективности. Это позволяет минимизировать начальные инвестиции и масштабировать технологию при доказанной пользе.
Эти технологии не предназначены для полной замены сотрудников. Они автоматизируют рутинные процессы, позволяя команде сосредоточиться на более сложных и ценных задачах. Например, LLM и RAG извлекают данные, генерируют аналитические отчёты или помогают с поиском информации, оставляя людям творческие и стратегические задачи.
На этапе тестирования мы проверяем модель на ваших данных, используя реальные кейсы и сценарии. Дальнейший мониторинг проводится на основе обратной связи команды, а также с помощью встроенных инструментов анализа качества ответов модели. Мы также внедряем функции подтверждения, чтобы пользователи могли проверять данные перед окончательной интеграцией в бизнес-процессы.
Сроки внедрения зависят от сложности инфраструктуры и объёма данных, с которыми предстоит работать. В среднем, процесс адаптации занимает от 4 до 12 недель. Мы выделяем этапы: аудит данных, настройка инфраструктуры, тестирование модели на выбранных данных и обучение сотрудников. Мы обеспечиваем минимизацию простоев в процессе работы.
RAG и LLM могут быть адаптированы под строгие требования безопасности, такие как локальная обработка данных (On-Premise), ограничение передачи данных в сеть и даже шифрование. Интеграция происходит с учётом всех стандартов безопасности, таких как GDPR или ISO 27001. Это позволяет выполнять обработку данных только внутри защищенной среды компании.
Уже в первый месяц вы увидите эффект:
- Оптимизация времени обработки информации, благодаря быстрому доступу к релевантным данным.
- Снижение нагрузки на сотрудников, так как модели справляются с рутинными задачами.
- Повышение точности аналитики и принятия решений.
- Для измерения эффективности мы внедряем ключевые показатели (KPI), такие как время на поиск информации, количество разрешённых запросов пользователей и увеличение производительности.
В отличие от стандартных LLM, которые генерируют ответы только на основе имеющихся знаний без проверки актуальности, RAG использует специализированные датасеты компании. Это позволяет:
- Получать точные и актуальные данные даже из нестандартной корпоративной базы.
- Уменьшить вероятность "галлюцинаций" модели (когда она генерирует ошибочные или фантазийные ответы).
Мы предоставляем полную поддержку, включающую обучение персонала и техническое сопровождение на всех этапах. Также возможно создание центра компетенции, который обеспечит адаптацию вашего внутреннего IT-отдела для работы с системой.
Модели RAG и LLM решают задачи именно там, где другие решения не справлялись: работа с массивами специализированных данных, высокая скорость обработки и контекстуальная генерация текстов. В отличие от универсальных решений, эта система адаптируется под конкретные бизнес-кейсы вашего предприятия, благодаря чему окупаемость обеспечивается в течение первых 6-12 месяцев.
Мы учитываем перспективы расширения и обновления в нашем решении. LLM-модели и RAG можно донастраивать по мере увеличения объёмов данных или изменения бизнес-процессов. Мы также консультируем вас по появлению новых трендов или подходов, чтобы ваша система всегда оставалась актуальной.
Стоимость интеграции варьируется от бюджета компании и уровня сложности задачи. Мы предлагаем модульный подход, начиная с малого функционала для тестирования и контроля эффективности. Это позволяет минимизировать начальные инвестиции и масштабировать технологию при доказанной пользе.
Эти технологии не предназначены для полной замены сотрудников. Они автоматизируют рутинные процессы, позволяя команде сосредоточиться на более сложных и ценных задачах. Например, LLM и RAG извлекают данные, генерируют аналитические отчёты или помогают с поиском информации, оставляя людям творческие и стратегические задачи.
На этапе тестирования мы проверяем модель на ваших данных, используя реальные кейсы и сценарии. Дальнейший мониторинг проводится на основе обратной связи команды, а также с помощью встроенных инструментов анализа качества ответов модели. Мы также внедряем функции подтверждения, чтобы пользователи могли проверять данные перед окончательной интеграцией в бизнес-процессы.
Резюме
Приятный бонус
AI-навигатор стал ключевым инструментом для обработки и систематизации знаний, что значительно повысило скорость и качество работы сотрудников
Ключевые эффекты
- Минус 50% времени на поиск данных
- Точность 92% выдачи релевантной информации
- База знаний стала простой в использовании без дополнительных инструкций
Этапы работы
- Очистка базы данных: удаление 70% дубликатов, сведение информации к структурированным «чанкам» (500–700 символов)
- Интеграция Retrieval-Augmented Generation (RAG): поиск релевантных данных на основе заданного запроса и использование LLM для генерации точных ответов
- Автоматизация обработки информации из сложных источников: видео (YouTube расшифровка), таблиц, голосовых сообщений и инструкций
- Сокращение времени на поиск информации: посещаемость корпоративной «Википедии» упала вдвое
- Точность ответов: достигнута 92% благодаря систематизации данных и адаптации AI
- Увеличение производительности сотрудников первой линии за счет автоматизации
- Организация внутренней документации заказчика: устранение пробелов и актуализация данных
- Сокращение времени на поиск информации: посещаемость корпоративной «Википедии» упала вдвое
- Точность ответов: достигнута 92% благодаря систематизации данных и адаптации AI
- Увеличение производительности сотрудников первой линии за счет автоматизации
- Организация внутренней документации заказчика: устранение пробелов и актуализация данных
Результат
Резюме
Приятный бонус
AI-навигатор стал ключевым инструментом для обработки и систематизации знаний, что значительно повысило скорость и качество работы сотрудников
Ключевые эффекты
- Минус 50% времени на поиск данных
- Точность 92% выдачи релевантной информации
- База знаний стала простой в использовании без дополнительных инструкций
Этапы работы
- Очистка базы данных: удаление 70% дубликатов, сведение информации к структурированным «чанкам» (500–700 символов)
- Интеграция Retrieval-Augmented Generation (RAG): поиск релевантных данных на основе заданного запроса и использование LLM для генерации точных ответов
- Автоматизация обработки информации из сложных источников: видео (YouTube расшифровка), таблиц, голосовых сообщений и инструкций
- Сокращение времени на поиск информации: посещаемость корпоративной «Википедии» упала вдвое
- Точность ответов: достигнута 92% благодаря систематизации данных и адаптации AI
- Увеличение производительности сотрудников первой линии за счет автоматизации
- Организация внутренней документации заказчика: устранение пробелов и актуализация данных
- Сокращение времени на поиск информации: посещаемость корпоративной «Википедии» упала вдвое
- Точность ответов: достигнута 92% благодаря систематизации данных и адаптации AI
- Увеличение производительности сотрудников первой линии за счет автоматизации
- Организация внутренней документации заказчика: устранение пробелов и актуализация данных
Результат
Узнайте, как ваш бизнес может получить выгоду от технологий AI и RAG. Закажите консультацию у CYFER уже сегодня!
Узнайте, как ваш бизнес может получить выгоду от технологий
AI и RAG. Закажите консультацию у CYFER уже сегодня!
AI и RAG. Закажите консультацию у CYFER уже сегодня!
Узнайте, как ваш бизнес может получить выгоду от технологий AI и RAG. Закажите консультацию у CYFER уже сегодня!
Узнайте, как ваш бизнес может получить выгоду от технологий
AI и RAG. Закажите консультацию у CYFER уже сегодня!
AI и RAG. Закажите консультацию у CYFER уже сегодня!
